I have just returned after a two-day engaging interdisciplinary conversation with more than 70 scientists, practitioners, faculty, and students from data science, machine learning, climate science, water science, agricultural sciences, and remote sensing representing both the academic and practice community at the 5th Annual Expeditions in Computing Workshop on “Understanding Climate Change from Data”.
Vipin Kumar – a wise interdisciplinary guru and the lead investigator of the NSF funded Expeditions in Computing – opened the workshop by articulating the overarching theme – develop methodologies to gain actionable insights and to inform policymakers about the nature and impacts of climate change – and highlighting major findings in relationship mining, complex networks, predictive modeling, and high performance computing.
What I found refreshing and intriguing is how this group of highly accomplished computer scientists worked with a range of domain experts – from hydrology, climate science, and remote sensing – and used tools from machine learning to ask interesting questions like: What can data scientists do to address problems in climate, water, and other physical sciences? What can domain experts do to sharpen and contextualize the tools of data science? What can data scientists and domain experts do together to develop actionable insight?
What can data scientists do?
Data scientists are agnostic learners. They do not care about the source or the type of data. They are like inquisitive detectives who can stare at data and spot patterns by developing and using objective tools. They usually have solid foundation in computer science and applications, statistical and mathematical modeling.
At this workshop, Arindam Banarjee was intrigued by the opening statement in Talagrand’s book on Generic Chaining: “What is the maximum level a certain river is likely to reach over the next 25 years?” (Having experienced a few feet of water in my house on three occasions, I feel a keen personal interest in this question.). To address similar questions, Arindam started by digging into spatiotemporal modeling of climate signals and asking: Are we there yet? He discussed why should we should be careful about using statistical models with high accuracy but limited stability (e.g., high variance) in the context of small sample size. For example, for predicting Indian Summer Monsoon rainfall, 60 years of data corresponds to just 60 training points, and any predictive model working such small sample needs to be rigorously tested for both predictive accuracy and stability.
What can domain experts do?
Domain experts are usually disciplinary. They care about disciplinary norms and build on established methods and prior knowledge. They are also inquisitive learners but within a bounded domain and seldom question traditional disciplinary assumptions rooted in many of their analysis, modeling, and findings.
Tim DelSole presented an example that illustrates why climate scientists might be skeptical of results from “big data” and introduces what data scientists can do to develop more convincing analyses of climate-variable relationships. His example showed how using a basic approach to generate a correlation map of geospatial variables — a common approach in spatial analyses — can create strong patterns of spurious time series correlations due to sampling variability — pure chance. Not only does this mean that a correlation map approach may be misleading, but it could encourage bad hypotheses for connections between variables.
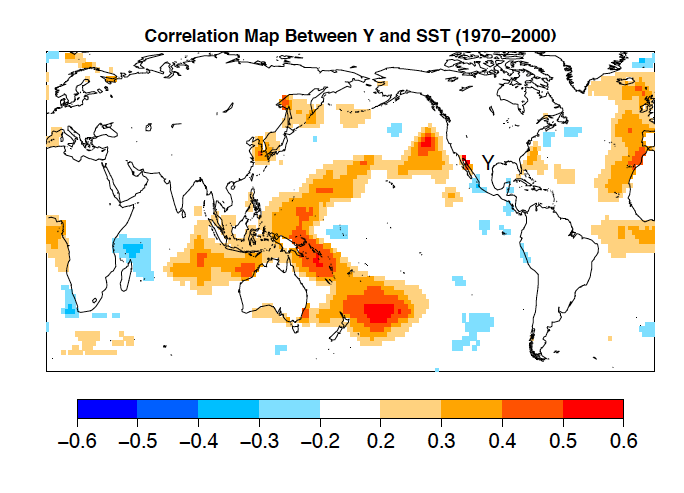
Correlation Map between Variable ‘Y’ and Sea Surface Temperature (SST) Correlations that are insignificant at the 5% level are masked out. In this example correlation map, a randomly generated time-series ‘Y’ correlated against a 30 year observed SST record produces an obvious pattern, which is due to sampling variability, as there is no relationship between the independently create random series and real observed SST data. There are more than 8000 SST grid points and high correlations can occur purely by chance. Spurious correlations tend to group in patterns, due to the pattern of variability in SSTs. (Figure courtesy of Tim DelSole)
What can data scientists and domain experts do together?
What was fascinating to me is that participants from this workshop were not caught up in framing the conversation on the superiority of machine learning versus domain expertise. Instead, most discussion centered around developing actionable insight to make an impact.
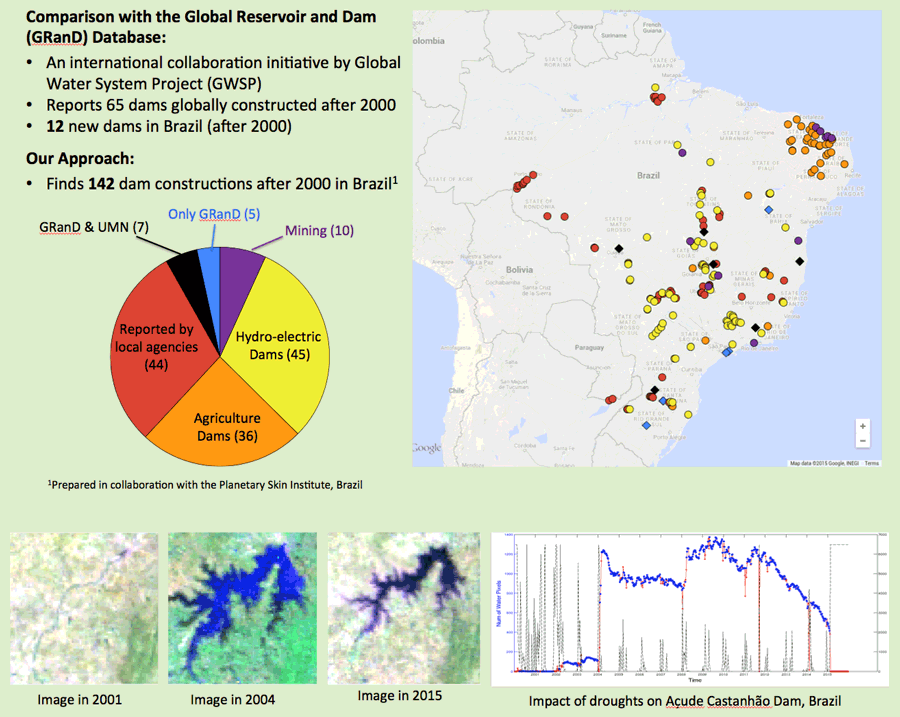
Detail from a poster from the workshop entitled Global Monitoring of Inland Water Dynamics: A Data-driven Approach presented by Anuj Karpatne*, Ankush Khandelwal, Varun Mithal, and Vipin Kumar (University of Minnesota).
Anuj Karpatne with other students from Vipin Kumar’s research group have shown how to monitor and track changes in surface water dynamics for any location in the world using remote sensing data. They have used supervised learning methods with physics guided labeling to detect and monitor changes in 2.5 km2 or larger water body anywhere in the world over the last 15 years. Their findings of these water bodies are independently verified using Google Maps. This independent verification of a data guided modeling is not only critical to develop confidence and trust in their findings but also to make them actionable for decision makers. For example, it was a particularly interesting to see that while the Global Reservoir and Dam Database reported only 12 new dams being constructed in Brazil since 2000; this methodology found and verified construction of 142 new dams. Clearly, reasons for this sharp contrast in number of new dams in Brazil need to be explored further; yet, this is a practical demonstration of what can be achieved when data scientists and domain experts work together to develop a tool that can provide actionable insight.
Neither data nor domain-centric science alone, but an insightful synthesis of data guided by domain specific expertise will allow us to judiciously determine which questions and which tools are appropriate for a given problem. For example: What variables should we measure and why? Which metrics should we use and why? How to interpret findings and relate them to outcomes that matter? How to communicate numbers with narratives for actionable outcomes to data-driven decision makers?
Inputs to this post from Arindam Banarjee, Tim DelSole, Auroop Ganguly, Vipin Kumar, and Amanda Repella are greatly appreciated.